
No matter how well tested and thought through, changes to code can cause failure—a common reason for this: latent errors and dark debt.
When pushing new code, we can only do so much testing. And, unfortunately, we can never fully mirror production. Unlike test environments, production is performed on a larger scale and has:
- Real users
- Higher security
- More external service dependencies.
By not being able to fully mirror these variables in pre-production phases, even the highest quality changes can be marred with latent errors and dark debt.
And, of course, this can be a significant source of concern and contribute to fear of deployment.
Understanding the Concept of Latent Errors
What are latent errors in programming? These are bugs that exist in service already in production but have not yet surfaced to awareness, making them virtually invisible.
You can also view latent errors as “dark debt,” an analogy coined by prominent reliability researcher John Allspaw.
Here are a couple of examples of dark debt.
Example 1:
An easy (and hopefully not all-too-familiar) example to illustrate latent errors and dark debt is a critical outage situation. Imagine the database you stored your customer’s account information goes down, and all of its data becomes corrupted. Ideally, this wouldn’t be an issue. You would restore this data from the backup to fix the problem. And that's exactly what you do. You restore from the backup, restart your database, sit back, and ... the restoration has failed.
You find out that, over time, small changes that were made in the database configuration were not included in the backup, leading to a mismatch in the database schema.
Now you have two problems to deal with: a critical outage and a latent error.
Example 2:
You find out that your exception handler has failed a critical operation because of a recently triggered error you didn’t know existed. Until today, that particular code path leading to the error has never been exercised—the result of this error: cascading failures within your exception handling routine.
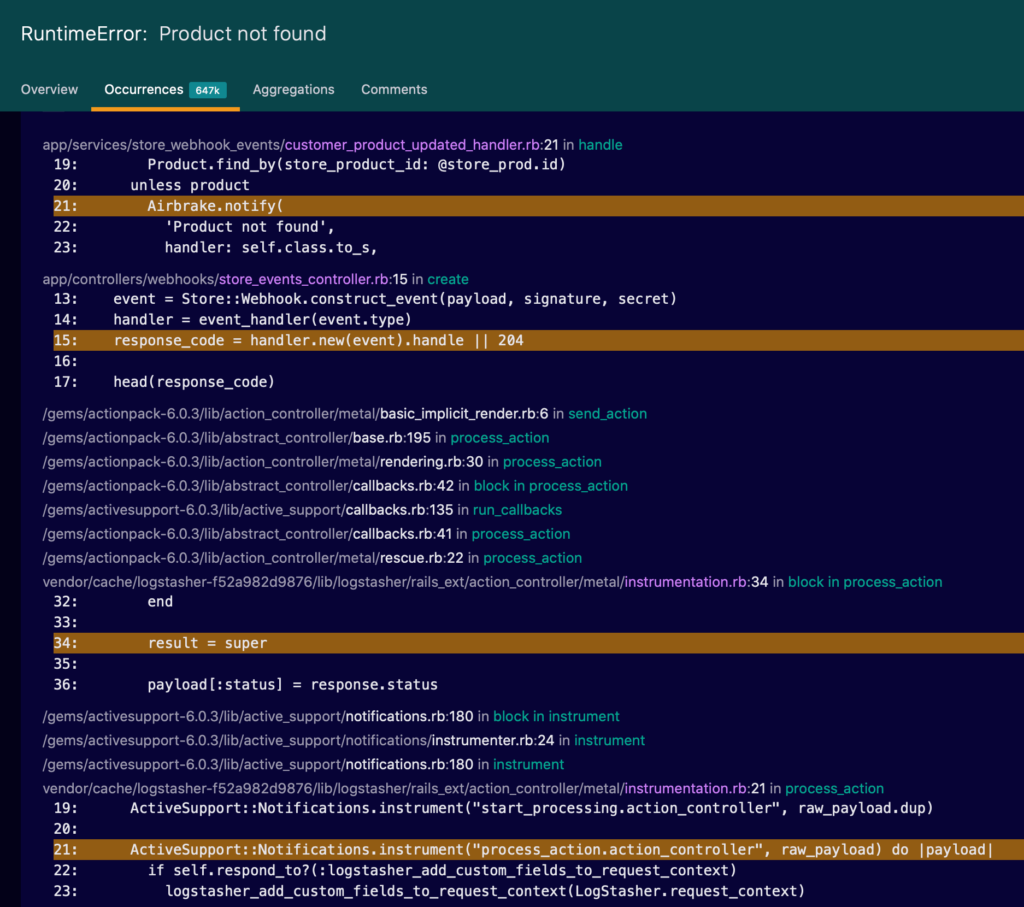
These two examples give you an idea of the issues a latent error can cause. In both cases, an unknown and invisible error resulted in catastrophic failure.
So, how do you tackle errors that are both unknown and virtually invisible?
How to Tackle Unknown Errors
When managing dark debt, there are two fundamental principles to keep in mind:
- Be aware that it exists
- Realize that you cannot fully ensure the quality of changes because it is not just about the change itself
You have to embrace failure as part of deploying new code.
That said, you’re not entirely helpless when it comes to latent errors. Here are some tips you can use to mitigate the damage done by dark debt.
1. Track and Address Your Known Errors
Handle errors you are aware of within your application. Even an error that doesn’t warrant an emergency can become a problem with future changes and deployments.
Find and keep track of errors with an error monitoring solution, like Airbrake. Airbrake Error Monitoring and Performance Monitoring tracks errors across applications and will tell you where an error is right down to the line of broken code. With a tool like this in your tech stack, you’ll quickly find old, new, and re-occurring errors quickly.
2. Provoke Your Code (Use Your Error Budgets)
Since latent errors are errors not yet activated, they will not be present in your logs.
The best way to find these errors is by provoking your code. If you have any error budget left, use it to initiate and execute rare paths within your code. The goal would be to exercise all parts of the code, such as error handling routines, edge cases, etc., to surface any latent errors that might exist.
There are multiple ways to provoke code. The effort itself is sometimes referred to as chaos testing - i.e., the deliberate acts of inflicting chaos to an environment and its applications.
Examples of chaos testing include:
- Surfacing input validation bugs via a fuzzer
- Using chaos testing platforms like Gremlin
Testing your code in production could impact users, so make sure you have room in your error budgets to conduct these tests. Start small, and work your way up.
3. Monitor for Anomalies and Unexpected Behavior
As highlighted by the Stella report, the easiest way to detect dark debt is through anomalies.
Anomalies allow you to foresee an issue before failure occurs. For example, an anomaly in traffic might tell you that the service is using the wrong destination for certain calls. Or that the code is forcefully making an integer a string.
Putting mechanisms in place to detect abnormal system and service behavior can raise awareness of a potential latent error. Here are a couple of those mechanisms:
- Metrical anomalies within various parts of the system to detect outliers in performance
- Log anomalies to detect outliers in behavior, such as new actions code is taking, absence of activity, etc.
These are only a couple of methods you can use to detect anomalies. While this system can help catch latent errors before they have time to impact your users, it won’t catch every error.
That’s where post mortems come in.
4. Perform Incident Post Mortems To Uncover the Root Cause Of an Error
A latent error is bound to cause an incident eventually. When this does happen, take the time to understand why this error occurred and what you can do to prevent it in the future. It’s crucial to ask technical questions about how the error occurred, but you should also investigate human errors, organizational inefficiencies, stress, luck, etc.
Here’s what Google has to say about conducting a post mortem report:
- What went well (i.e., the autoscaling worked, alert triggered timely, the engineer responded quickly)
- What went wrong (i.e., the engineer had no one to escalate to, autoscaling made the problem hard to diagnose, etc.)
- Where we got lucky (i.e., John was on call for another incident and could help out, the incident occurred late at night when traffic was low).
Your code will never be error-free, but conducting post mortems is an excellent way to prevent the same errors from cropping up again.
Conclusions
Latent errors are bound to happen. While you can't fully prevent them, you can use the tips outlined in this article to minimize the damage they do.
It starts with being aware that this dark debt exists and accepting it as a fact of deploying new code. From there, you can start to track errors, provoke errors, monitor for anomalies, and, most importantly, learn from mistakes.
An easy way to detect errors before they impact users is with error monitoring software. If you haven't done so already, try Airbrake Error and Performance Monitoring free for 30 days. With this trial, you'll have access to unlimited error and performance monitoring, unlimited integrations, unlimited user accounts, and unlimited projects.
Now go forth, and deploy fearlessly!
-Jan-20-2023-08-57-42-2088-PM.png)
-Jan-20-2023-08-58-59-1985-PM.png)