I interviewed Joe Stump, former Digg lead architect, founder of SimpleGeo and now the founder of project management tool Sprintly. We covered how he built software at Digg, how that changed as he transitioned to SimpleGeo, what he’s learned about building and managing software teams, and why he chose Sprintly as his next project to focus on.
Justin: Thanks for doing the interview. I’m really interested in A) how you guys build software at Sprint.ly, and B) how you came up with the idea. I’m assuming part of the reason is that you didn’t love the way you built stuff at previous companies, so you decided to start Sprint.ly. Is that a reasonable guess?
Joe: Sort of. I’ve always been proud of the way that both my teams and myself have built software. At SimpleGeo we had a phenomenal team, we had a phenomenal process in place. And as far as the actual building and distributing of software went… the development cycle at Geo was very different than anywhere else I’ve worked at since. We literally had one queue. Everybody was capable of doing everything. So we had senior engineers who said “I don’t really care if you were a dev ops person in your last company, you’re an engineer now and you’re going to code. I don’t really care if you didn’t write scripts as an engineer at your last company, you’re going to write them at this company.” So we just had one queue that was literally a big board. That was the way we developed at Geo.
I built Sprint.ly because is every company I worked at consistently had a problem communicating the software development process to the rest of the business. A lot of the tools in this space (I think largely by design) are very esoteric and are built in a way to obfuscate what’s going on inside the software development black box.
I’m kind of a genetic freak on the development side. I have a business degree, not a computer science degree. So I’d often go into these product meetings where the business and software development comes together to talk about how things are going. There would always be intense frustration on the business side. You had people saying “I have no idea what’s going on. I’ve got $500,000 in an advertising and marketing budget that’s lined up on this release and you literally can’t tell me whether it’s going to be ready this quarter or next quarter?”
So we built Sprint.ly, and have been trying really hard to create a tool that demystifies the software development process. It gives businesses a single place for both the business and software development teams to participate in the product development process.
Justin: That makes a lot of sense. You mentioned at SimpleGeo, you guys had a queue system for managing software development. Can you talk a little more about that? How did you arrive at that process? How well did it work? What were some pitfalls?
Joe: It works great. We had, as far as I can remember, one late release. 30 minutes late. And the only reason it was 30 minutes late was because we didn’t have a design asset. We built some pretty groundbreaking database technology while we were at SimpleGeo. I don’t remember any fights amongst development. There was no us versus them when it came to the business or operations. A lot of times, operations and development can be at odds with one another.
My major takeaway from the SimpleGeo experience was the [task] queue we had on the big board. Everybody knew what everyone was working on at all times. We never had the BD guy never came up and said “hey, what’s Malone working on?” It was on the big board. He walked past it every time he walked into his office.
So I think that transparency works really well. Then the other thing that I think worked really well was this notion of calling everyone an engineer. I pushed very hard on the tech side to make this happen. You can have areas where you’re stronger than others, but at the end of the day we’re all responsible for this piece of technology. By calling everybody an engineer, instead of saying “you’re ops and you’re an engineer and you’re a frontend guy”, it really broke down barriers you normally see.
On any given day at Sprint.ly you’ll see a DevOps-ish person working with somebody that has a mapping backend, writing shell scripts. Then, you’d see guys that normally were coding help some DevOps people work through some Python things they wanted to build or needed to patch or whatever. So those were the two things I took away as really being positive. One is that we need to get over this notion that as developers, we need to insulate ourselves from the rest of the business. We’re all adults and perfectly capable of understanding the business if you take a little bit of time to explain and give developers access to the data. And the other big takeaway is that really, everybody has to own product. I really don’t care if you’re writing JavaScript or writing Puppet scripts, we all have the same responsibility. I think this approach led to a really good culture. Like I said, there wasn’t a lot of infighting or problems on the tech side about who should own what.
Justin: You mentioned engineering guys, devops guys, were all engineers. Is there any downside to that approach, where you have people that are more talented at one thing maybe spending their time on stuff they may not be as good at?
Joe: You can probably make an argument for that, but I look at those downsides as being far outweighed by the benefits of building people up. One of the senior DevOps people at SimpleGeo is now a lead architect and senior engineer. He said by the time he left SimpleGeo he realized he liked the whole coding thing. It’s fun. And that wouldn’t have happened if we hadn’t encouraged everybody to code.
The downside of pigeonholing people is what I call the buddy rule. We had a guy there, Schuyler Erle. He wrote mapping hacks before Google Maps existed. He literally works with the World Bank to do disaster mapping. He went to Haiti when they had that big earthquake.
So he became an expert in mapping and geospatial technologies, right? And because Schuyler was coding, and because I forced him to work with the other engineers and stuff, he was exposed to technologies he otherwise wouldn’t have known about. In fact, in the conversations I’ve had with him afterwards, he mentioned that he really learned how to build software correctly at SimpleGeo. I forced them to do unit tests, write management scripts, and all this other stuff.
On top of that, if Schuyler had left the company towards the end, we would’ve had the knowledge to continue. Now it would’ve been a blow and it would’ve sucked because Schuyler is probably one of the top five people in the world at what he does so it sucks to lose somebody like that. But because I forced people to work together in this structure and everybody had to have ownership of what they were doing, I think slightly less productivity from Schuyler was well worth it. We actually built up a team of experts with expertise in that area [mapping] as opposed to just having one person that did it all.
Justin: That makes sense. So at Simple Geo, you guys had this queue system. Everyone was an engineer. Can you talk a bit about how you guys built software at Digg? What was that process like?
Joe: Yeah, I was there for about two and a half years. When I started there were 7 engineers and 18 or 19 people. When I left there were 35 people in the tech department and probably close to 100 people in the company. When I started there, it was chaos. We had Bugzilla but nobody really used it. Most product tracking stuff was done in Excel spreadsheets that weren’t shared with the team. Most products were structured at a milestone level rather than at an implementation level. We had no coding standards. We weren’t using any frameworks. Everybody had their own styling. It was chaos. So we hacked on whatever we were told to hack on.
We ended up getting a new VP of engineering and a new director of product, and it really brought what I would call traditional agile methodology into Digg. By the time I left, we had basically rewritten Digg on top of frameworks that myself and an application architect had put together. We had coding standards implemented, and we broke everybody up into teams. Depending on the team, there were anywhere from three to five people. We had an app team; they were responsible for the application layer at Digg. We had what we called an admin and data team, and basically what they did is they built internal tools and worked with Digg R&D to push out some of the cooler features we had, like Digg suggest and stuff like that.
Their job was to take those harebrained experiments that were slapped together with glue and twigs and make a production-ready process. We had a backend infrastructure team that worked closely with ops. I was on that team. Then we had an API team. The API was a hugely successful API for its time. We had thousands of people that were working with it.
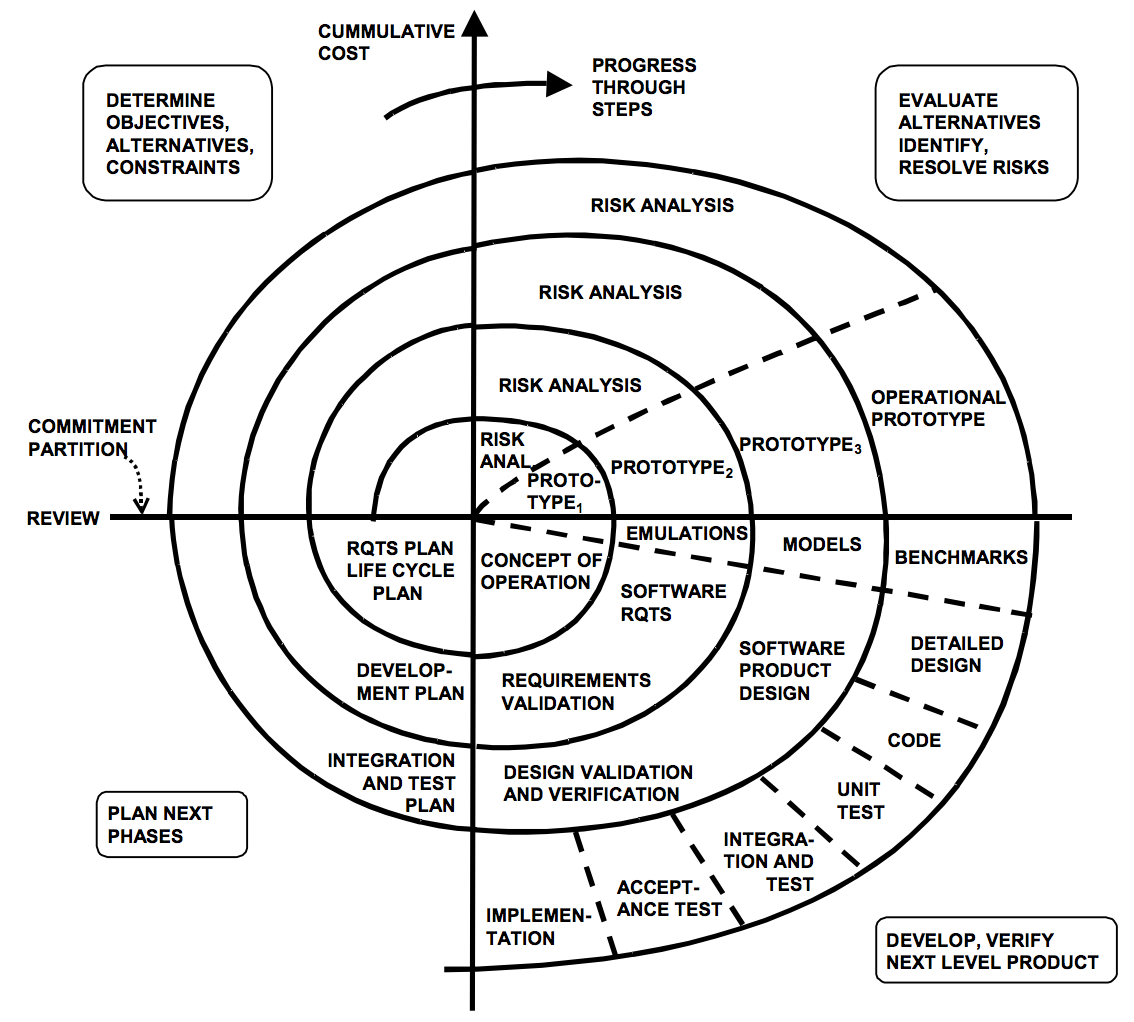
Each of those teams had their own sprints, which were 4-week iterations at Digg. And we also had a Scrum where all the Scrum assets were put together and coordinated across all the different things that were going on. Our release process was to cut a major version into minor versions like 7.5, 7.6, and that would be an integration branch. We had QA and a build-and-release, a release person that would basically handle merging all of those sprints in and then shuttling that out.
So at any given time we had probably two or three major versions of Digg in development at any given time. One of those is what most people would call stable, so it was out in production. It was a separate branch and whenever we needed to fix things we would either fix it in the branch and port it back to master or fix it in master and port it to the branch and deploy it from there. And then the other branches were usually one for each team, and consisted of whatever major feature they were working on.
Justin: So you’ve been doing Sprint.ly now for a few years. How do you guys build software now and how does it compare to when you started?
Joe: So the software development process at Sprint.ly hasn’t changed as far as what gets built and how.
Justin: How many developers do you have?
Joe: Three, so we’re a real small team. I’ve kept up with the queues. I really like how the queues work. What we do is we have a Someday list, which is stuff we’d like to do someday. Then we have a backlog, which is usually high priority live bugs, and things we’ve all agreed we’re going to work on next. From there I like the developers to pick and choose.
Personally, I like working on two or three things at a time because I tend to get bored with one thing. There’s a rough priority to the backlog, but if you want to skip one and do an easy ticket today because you went for a long run last night, that’s fine. I don’t really care.
We’re pretty loosey-goosey on that. We don’t do sprints. We coordinate major milestones, but that’s usually for marketing purposes. It’s not really for the tech or anything.
Justin: Do you coordinate them based on date or priority? How do you do that?
Joe: It really depends. So we don’t really believe in dates. I’m a firm believer that you’re either date-driven or you’re feature-driven.
Justin: I happen to agree.
Joe: We’ll always be feature-driven. It doesn’t matter if we release Sprint.ly 2.0 on September 1stor September 5th. That doesn’t really matter. So really the way that we develop is basically we develop in future branches, put them in pull requests and what we’ll do is if it’s a major release and we want to do some press or write a blog post about it, we’ll group them up into a staging branch basically. And from there, everything is automated: automated tests, frontend, backend. We have a build and deploy process. So every time something is merged into master or staging, in ten minutes, with the push of a button, you’re out on production.
I have a part of the brain that is I don’t want to hear about your cool idea. Just send me your pull request. That’s where a lot of our development activity actually happens is in the pull requests.
Justin: What tools do you guys use to manage all of this?
Joe: Well, we of course use Sprint.ly. Sprint.ly is really our idea repository. That’s where we collaborate around thinking through ideas, posting mock-ups and wireframes, stubbing out the general requirements for different features, or whatever it is. Sprint.ly is very tightly integrated with Github. We use Github to store code and whatnot. As far as the build and deploy process, we use Jenkins for our CI server. We use Sauce Labs and Mocha Chai for frontend tests. Everything is deployed on top of AWS and we use Fabric to glue everything together.
Justin: Can you talk me through how you guys deal with errors when they crop up and your code review process?
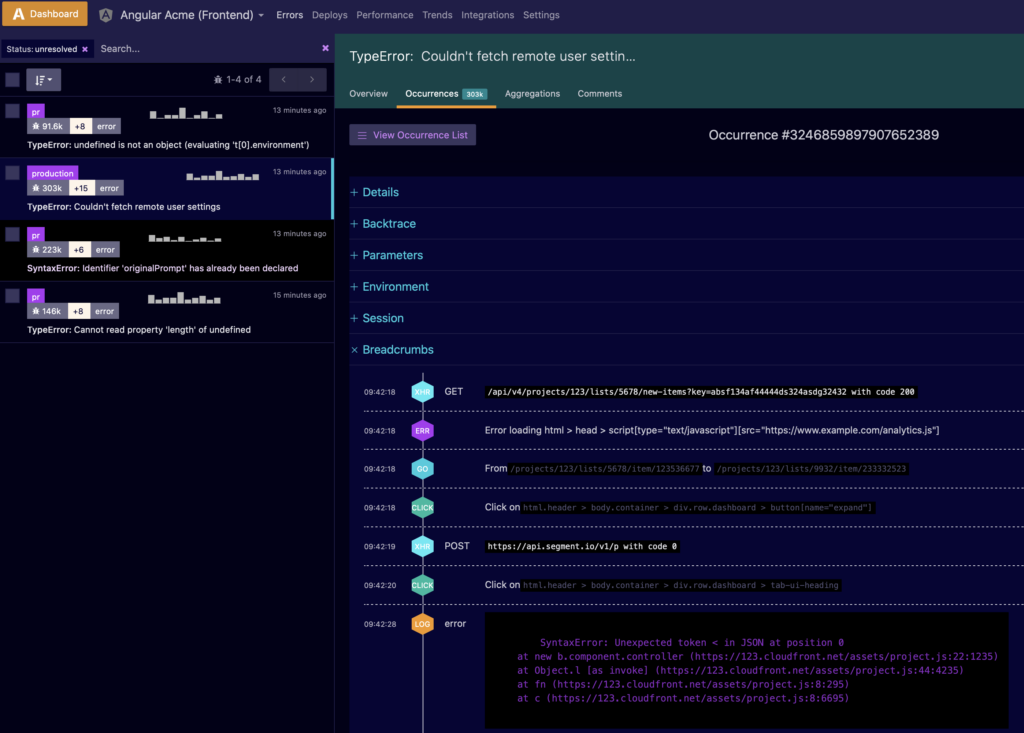
Joe: Sure. When errors pop up, we use a number of tools to get that data. That can be everything from an exception logger to Tracelytics. I can’t say enough good things about Tracelytics; it’s an amazing product. They’re called TraceView now.
Justin: Do you guys use like New Relic or anything like that?
Joe: Tracelytics is a competitor to New Relic. It’s in my opinion a superior product. It’s very well done. We’ve been dabbling with another product called Caliper, and Caliper is effectively a New Relic or Tracelytics for frontend frameworks. We’re a very heavy backbone app. We have that, and usually what will happen is we’ll get either a bug report from the customer or one of those systems will say something’s wrong.
Our process depends greatly whether it’s a super edge case that’s, say, only affecting people running old versions of Opera. If so, probably not going to worry about that. If it’s a high priority big bug, basically what I’ll do is create a ticket and send it to the people I think need to work on it. We will cut a quick branch and write a regression test first. We’re really big on doing test-driven development, so we’re always writing regression tests to fix a bug. If it’s a pants-on-fire thing we may not even do a pull request. At that time it’s pure firefighting. And then it goes out during a normal build deploy process.
Justin: What does that deployment process look like? Roughly how often do you guys deploy?
Joe: It really depends. Right now we’re kind of log jammed and have a bunch of pull requests with some pretty major refactoring stuff, so we’re only deploying a couple times a week. Otherwise, we’re deploying anywhere from once a day to six times a day. It really depends.
The build and deploy process at Sprint.ly is 100% automated. You push a button to deploy. So the tool chain that we have, you use AWS with Chef and Fabric. So I can literally do “make app server” and 15 minutes later I have a fully functional, production-ready app server. For the build process, any commits to master is run through a full build of full back-end testing. After that’s done, we build a Debian package out of the code including all the migrations and everything. We then use a tool called RepoMan that was built by a colleague of mine at Digg. It’s a RESTful JSON API to Debian repositories. So Jenkins actually does an HTTP POST to our app repo that says hey, staging app repo, here’s a new package. Then the next build stuff is deployed at the staging.
So everything’s fully automated up to that point, then once you check the staging, there’s two Fabric commands. One is to promote the package from a staging repository into a production repository and the next one does an apt-get update, apt-get install to deploy it.
Justin: So, last question, since you have so much going on, how do you guys prioritize different features and product feedback that you get from customers?
Joe: So the way we prioritize customer feedback, right now anyway, is solely focused on churn. The way I decide what major feature to build next is I go into our exit surveys and I look through the “What could we have done to keep you?” answers. I look for themes. I put those in a spreadsheet, so each theme goes at the top of a column. I go through every single exit survey and put a 1 under each column that gets a message and then I roll those up.
When I did that for version 1.0, 27% of people in our exit survey said that the UI degraded as you added more and more items and it became difficult to manage them all. So, we drilled down on that and majorly improved it.
Justin: I see. So you guys basically have one major business metric you’re trying to improve, and then filter product feedback and features through that metric. Well that is pretty much all I have. Is there anything else you want to discuss?
Joe: No. If anybody out there wants to try Sprint.ly, just let me know. I’m Joe@sprint.ly, happy to give you a demo.